Cómo elegir la prueba estadística correcta para tu TFG en 2026 (árbol de decisión paso a paso)
Acabas de recoger tus datos y abres SPSS o jamovi. Hay decenas de pruebas estadísticas en el menú y no sabes cuál corresponde a tu diseño. Elegir mal en ese momento puede invalidar toda tu sección de resultados — y es uno de los errores más frecuentes que los tribunales detectan en los TFG de ciencias sociales, de la salud y de educación. Este artículo te da un árbol de decisión claro y accionable para saber, en menos de cinco minutos, qué prueba estadística debes aplicar según tus variables, tu hipótesis y el tamaño de tu muestra.
No asumes conocimientos previos de estadística avanzada: solo necesitas saber qué tipo de variables tienes y qué relación quieres estudiar. Cada paso del árbol te lleva a una prueba concreta, con el criterio que la justifica y el software más habitual donde ejecutarla.
Por qué elegir mal la prueba estadística puede hundir tu TFG
El análisis estadístico no es un trámite técnico que se añade al final. Es el mecanismo que determina si tus conclusiones son válidas o no. Un tribunal que detecta que has aplicado una prueba paramétrica a datos que claramente no siguen una distribución normal — o que has usado una t de Student cuando tienes tres grupos — cuestionará toda tu sección de resultados, independientemente de lo bien escrita que esté la introducción.
La elección de la prueba estadística debe quedar justificada en el apartado de metodología de tu TFG. No basta con nombrar la prueba; tienes que argumentar por qué corresponde al diseño, el tipo de variable y las características de los datos. Si sigues los cuatro pasos de este árbol de decisión, tendrás esa justificación construida de forma natural.
Para poner el análisis en contexto desde el principio, revisa cómo debes presentar el enfoque metodológico global antes de entrar en la estadística: la guía sobre cómo redactar la metodología de un TFG te ayudará a encajar el análisis inferencial dentro del diseño general de la investigación.
Paso 1 — Define el objetivo estadístico de tu hipótesis
El primer filtro del árbol de decisión es la pregunta más fundamental: ¿qué quieres demostrar con tus datos? Casi todos los análisis estadísticos de un TFG responden a uno de estos tres objetivos:
- Comparar grupos: ¿existe diferencia entre el grupo A y el grupo B en una variable? Por ejemplo: ¿difieren las puntuaciones de ansiedad entre estudiantes con y sin apoyo tutorial?
- Estudiar asociación o correlación: ¿están relacionadas dos variables sin que una cause la otra? Por ejemplo: ¿a mayor número de horas de estudio, mayor calificación?
- Predecir o modelar: ¿puede una variable (o varias) predecir el valor de otra? Por ejemplo: ¿el nivel socioeconómico predice el rendimiento académico?
Esta distinción es crucial porque cada objetivo corresponde a una familia diferente de pruebas. Confundirlos es el primer error. Muchos estudiantes aplican una correlación cuando en realidad su hipótesis compara dos grupos independientes — y eso es una prueba t, no una correlación de Pearson.
Paso 2 — Identifica el tipo de tus variables
El tipo de variable es el segundo filtro del árbol y uno de los más determinantes. En estadística distinguimos tres grandes categorías que se corresponden con niveles de medición:
| Tipo de variable | Nivel de medición | Ejemplos habituales en TFG | Operaciones permitidas |
|---|---|---|---|
| Nominal | Categórica sin orden | Sexo, titulación, modalidad de estudio | Frecuencias, proporciones |
| Ordinal | Categórica con orden | Escala Likert (1-5), nivel de satisfacción, curso académico | Medianas, rangos, percentiles |
| Continua (intervalo/razón) | Numérica con intervalos iguales | Peso, temperatura, puntuación en test estandarizado, tiempo de reacción | Medias, desviaciones típicas, operaciones aritméticas |
La distinción entre ordinal y continua es donde más confusión hay. Las escalas Likert de 5 o 7 puntos son técnicamente ordinales, aunque en la práctica muchos estudios en ciencias sociales las tratan como continuas cuando hay suficientes ítems y se trabaja con la puntuación total de una escala validada. Si no tienes claro el estatus de tu escala, consulta los estudios de validación del instrumento que estás usando — suelen especificar qué tipo de análisis es apropiado. Antes de ejecutar cualquier análisis comparativo, conviene además comprobar la consistencia interna del cuestionario: la guía sobre cómo calcular el alfa de Cronbach en Jamovi y SPSS te explica ese paso previo esencial para escalas Likert.
Paso 3 — Cuenta el número de grupos o variables
Una vez sabes el objetivo y el tipo de variable, el tercer filtro es cuántos grupos comparas o cuántas variables relacionas:
- Comparación: ¿uno, dos o más de dos grupos? ¿Los grupos son independientes (personas diferentes) o relacionados (mismas personas en distintos momentos)?
- Asociación: ¿dos variables? ¿Una dependiente y una o varias independientes?
- Predicción: ¿cuántos predictores tienes? ¿Una variable dependiente continua o categórica?
Este paso elimina la mayoría de las confusiones entre t de Student y ANOVA, o entre chi-cuadrado de independencia y McNemar. La regla es sencilla: si comparas dos grupos independientes con variable continua, es t de Student; si comparas tres o más grupos, es ANOVA (o su alternativa no paramétrica, Kruskal-Wallis). Si ya tienes claro que tu diseño implica dos grupos independientes con variable continua, la guía sobre cómo hacer la prueba t de Student en SPSS y Jamovi paso a paso te muestra la ejecución completa con interpretación de resultados.
Paso 4 — Comprueba el supuesto de normalidad
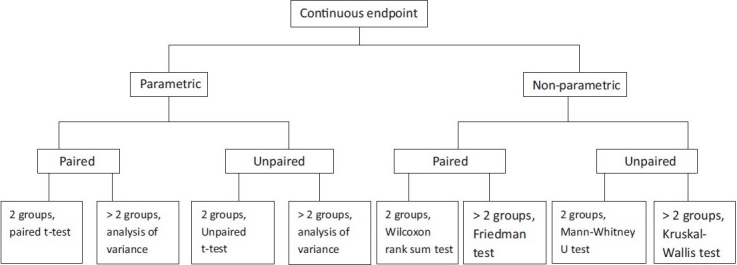
El cuarto y último filtro determina si puedes aplicar pruebas paramétricas (más potentes, pero con supuestos más estrictos) o debes usar alternativas no paramétricas. Las pruebas paramétricas asumen que la variable dependiente sigue una distribución aproximadamente normal en la población. Si ese supuesto se viola con claridad, debes usar la alternativa no paramétrica equivalente.
Para comprobar la normalidad existen dos estrategias complementarias que debes usar juntas:
- Pruebas formales de normalidad: Shapiro-Wilk (recomendada cuando n < 50 por grupo) y Kolmogorov-Smirnov-Lilliefors (para n ≥ 50). Si el p-valor es ≥ .05, no se rechaza la normalidad. Consulta la guía completa sobre prueba de normalidad Shapiro-Wilk vs Kolmogorov-Smirnov y cómo interpretarlas en SPSS para ver cómo ejecutarlas e interpretarlas paso a paso.
- Exploración visual: histograma y gráfico Q-Q (cuantil-cuantil). Una distribución aproximadamente normal produce un histograma en forma de campana simétrica y puntos alineados sobre la diagonal en el Q-Q plot. La exploración visual es especialmente útil cuando la muestra es pequeña y las pruebas formales tienen poca potencia.
Además de la normalidad, las pruebas paramétricas asumen homocedasticidad (igualdad de varianzas entre grupos) cuando comparas más de un grupo. La prueba de Levene es el test estándar para verificar este supuesto en SPSS y jamovi.
El árbol de decisión completo (tabla de referencia rápida)
La siguiente tabla resume el árbol de decisión completo. Identifica tu fila aplicando los cuatro pasos anteriores y encontrarás la prueba recomendada y su alternativa no paramétrica cuando proceda.
| Objetivo | Variable dependiente | Grupos / estructura | Normalidad | Prueba paramétrica | Alternativa no paramétrica |
|---|---|---|---|---|---|
| Comparar grupos | Continua | 1 grupo vs valor de referencia | Sí / No | t de Student para una muestra | Prueba de Wilcoxon (una muestra) |
| Comparar grupos | Continua | 2 grupos independientes | Sí | t de Student para muestras independientes | U de Mann-Whitney |
| Comparar grupos | Continua | 2 grupos independientes | No | — | U de Mann-Whitney |
| Comparar grupos | Continua | 2 mediciones en el mismo grupo (pre-post) | Sí / No | t de Student para muestras relacionadas | Prueba de Wilcoxon (rangos con signo) |
| Comparar grupos | Continua | 3 o más grupos independientes | Sí | ANOVA de un factor | Kruskal-Wallis |
| Comparar grupos | Continua | 3 o más grupos independientes | No | — | Kruskal-Wallis |
| Comparar grupos | Continua | 3 o más mediciones repetidas (mismo grupo) | Sí / No | ANOVA de medidas repetidas | Prueba de Friedman |
| Asociación | Nominal vs Nominal | 2 variables categóricas independientes | N/A | — | Chi-cuadrado de Pearson (o exacta de Fisher si celdas < 5) |
| Asociación | Continua vs Continua | 2 variables cuantitativas | Sí | Correlación de Pearson (r) | Correlación de Spearman (ρ) |
| Asociación | Ordinal vs Ordinal / Continua | 2 variables, al menos una ordinal | No / N/A | — | Correlación de Spearman (ρ) |
| Predicción | Continua | 1 predictor continuo | Residuos normales | Regresión lineal simple | Regresión de Theil-Sen (robusta) |
| Predicción | Continua | Varios predictores | Residuos normales | Regresión lineal múltiple | — |
| Predicción | Nominal (dicotómica) | Uno o varios predictores | N/A | Regresión logística binaria | — |
Las pruebas más habituales en TFG: guía de uso
t de Student para muestras independientes
Cuándo usarla: compares las medias de una variable continua entre dos grupos distintos (p. ej., hombres vs. mujeres en una escala de bienestar). Requiere que los datos sean aproximadamente normales y que las varianzas de ambos grupos sean homogéneas (prueba de Levene). Si la prueba de Levene arroja p < .05, usa la corrección de Welch, que SPSS aplica automáticamente en la segunda fila de resultados.
Alternativa: U de Mann-Whitney cuando la normalidad o la homocedasticidad no se cumplen, o cuando trabajas con una escala ordinal.
ANOVA de un factor
Cuándo usarla: comparas las medias de una variable continua entre tres o más grupos independientes (p. ej., diferencias de rendimiento entre tres titulaciones). Un resultado significativo (p < .05) solo indica que hay diferencias en algún lugar entre los grupos; debes complementarlo con pruebas post hoc (Tukey, Bonferroni) para localizar entre qué pares de grupos existe la diferencia.
Alternativa: Kruskal-Wallis. Cuando el ANOVA no es viable por incumplimiento de normalidad, la prueba de Kruskal-Wallis con post hoc de Dunn es el camino correcto: te explica cómo ejecutarla e interpretar los rangos medios en SPSS y jamovi.
Chi-cuadrado de Pearson
Cuándo usarla: estudias la asociación entre dos variables categóricas. Por ejemplo, ¿existe relación entre el tipo de centro escolar (público/concertado/privado) y el nivel de uso de tecnología educativa (alto/medio/bajo)? Los datos deben cumplir el supuesto de frecuencias esperadas: ninguna celda debe tener una frecuencia esperada inferior a 5. Si ese supuesto se viola, usa la prueba exacta de Fisher (solo disponible para tablas 2×2) o agrupa categorías. Si necesitas ver la ejecución completa paso a paso, la guía sobre cómo hacer una prueba de chi-cuadrado en SPSS paso a paso cubre desde la tabla de contingencia hasta la interpretación del V de Cramér.
Medidas de asociación complementarias: Phi (tablas 2×2), V de Cramér (tablas mayores), Coeficiente de contingencia.
Correlación de Pearson (r)
Cuándo usarla: estudias la relación lineal entre dos variables continuas y ambas se distribuyen normalmente. El coeficiente r oscila entre -1 (relación negativa perfecta) y +1 (relación positiva perfecta). Un valor de r próximo a 0 indica ausencia de relación lineal, aunque podría existir una relación curvilínea.
Alternativa: Correlación de Spearman (ρ) cuando las variables son ordinales o cuando no se cumple la normalidad. Spearman trabaja con rangos en lugar de valores brutos y es más robusta a valores atípicos.
Regresión lineal simple y múltiple
Cuándo usarla: quieres predecir una variable dependiente continua a partir de uno o varios predictores. La regresión múltiple es especialmente frecuente en TFG de ciencias de la educación, psicología y ciencias de la salud. Sus supuestos clave son: linealidad, independencia de residuos (test de Durbin-Watson), homocedasticidad de residuos y normalidad de residuos (no de las variables originales).
Regresión logística binaria
Cuándo usarla: la variable dependiente es dicotómica (sí/no, aprobado/suspenso, presente/ausente). No requiere normalidad. Los coeficientes se interpretan como odds ratios (OR): la razón de probabilidades de que ocurra el evento al aumentar el predictor en una unidad.
Si tu TFG incorpora métodos cualitativos y combinados, la lógica del árbol de decisión aplica solo a la parte cuantitativa. Para la parte cualitativa — como grupos focales, entrevistas o análisis del discurso — el enfoque es distinto: en la guía sobre cómo hacer un grupo focal con guión, moderación y análisis encontrarás el equivalente metodológico para datos no numéricos.
5 errores frecuentes al elegir la prueba estadística
- Aplicar pruebas paramétricas sin verificar la normalidad. No es suficiente con asumir que los datos son normales porque la muestra es “grande”. Con n > 30 las pruebas paramétricas son más robustas, pero sigue siendo necesario reportar que se verificó el supuesto. Un tribunal riguroso lo pedirá.
- Usar t de Student cuando hay tres o más grupos. La t solo compara dos grupos. Si tienes tres condiciones experimentales y aplicas tres t de Student (A vs B, A vs C, B vs C), inflas artificialmente el error de tipo I (el riesgo de encontrar diferencias por azar). El ANOVA controla ese problema comparando todos los grupos simultáneamente.
- Confundir correlación con comparación. Si tu hipótesis dice “los alumnos del grupo experimental puntúan más alto que los del grupo control”, es una comparación de medias (t de Student o Mann-Whitney). Una correlación de Pearson entre grupo (variable categórica 0/1) y puntuación no es el análisis correcto, aunque a veces produzca el mismo p-valor.
- Ignorar la distinción entre medidas independientes y repetidas. Si mides la misma persona antes y después de una intervención, los datos no son independientes. Usar la t para muestras independientes en ese caso es técnicamente incorrecto; debes usar la t para muestras relacionadas (o Wilcoxon).
- Tratar las escalas Likert siempre como continuas. Una sola pregunta Likert de 5 puntos es ordinal. Si tu cuestionario tiene, por ejemplo, 20 ítems y usas la puntuación total, hay más debate y algunos autores aceptan tratarla como continua — pero debes justificarlo con la referencia metodológica del instrumento validado.
Definir correctamente el tipo de objetivos y de variables desde el diseño de tu investigación evita la mayoría de estos errores. Te recomendamos revisar nuestra guía sobre metodología del TFG: cuantitativa, cualitativa y mixta con ejemplos antes de diseñar el instrumento de recogida de datos, y así alinear el diseño con el análisis desde el principio.
Preguntas frecuentes
¿Puedo usar siempre una prueba no paramétrica para evitar verificar la normalidad?
Técnicamente sí, pero no es lo recomendable. Las pruebas no paramétricas son menos potentes que las paramétricas cuando los supuestos de estas últimas sí se cumplen — es decir, necesitas una muestra más grande para detectar el mismo efecto. Además, los tribunales pueden interpretar el uso sistemático de no paramétricas como una evasión de los supuestos, no como una elección justificada. Usa la alternativa no paramétrica cuando haya una razón real: normalidad rechazada, escala ordinal o muestra muy pequeña.
¿Qué hago si mis datos de escala Likert son ordinales pero quiero usar ANOVA?
Si trabajas con la puntuación total de una escala validada (por ejemplo, el total de 20 ítems del Cuestionario de Burnout de Maslach), muchos investigadores la tratan como continua y aplican ANOVA argumentando que la distribución de puntuaciones totales se aproxima a la normal. Debes justificarlo citando los estudios de validación del instrumento. Si no tienes ese respaldo, usa Kruskal-Wallis, que es el equivalente no paramétrico de ANOVA para datos ordinales o no normales.
¿Cuándo se usa la prueba exacta de Fisher en lugar de chi-cuadrado?
La prueba exacta de Fisher se usa cuando tienes una tabla de contingencia 2×2 y al menos una celda tiene una frecuencia esperada inferior a 5. En ese caso, el estadístico chi-cuadrado no es fiable porque su distribución teórica no se ajusta bien a frecuencias esperadas tan bajas. SPSS calcula automáticamente la significación exacta de Fisher junto con chi-cuadrado; simplemente usa ese valor cuando se cumpla la condición de celdas pequeñas.
Mi Shapiro-Wilk da p = .03. ¿Debo pasar obligatoriamente a una prueba no paramétrica?
No necesariamente. El resultado de Shapiro-Wilk es solo una de las evidencias que debes considerar. Examina también el histograma y el Q-Q plot: si la desviación de la normalidad es leve y la muestra es moderada o grande (n ≥ 30), las pruebas paramétricas son bastante robustas. Si la distribución muestra asimetría pronunciada o valores atípicos extremos, sí conviene usar la alternativa no paramétrica. En cualquier caso, documenta tu razonamiento en la metodología.
¿Puedo usar más de una prueba estadística en el mismo TFG?
Sí, y es lo habitual en TFG con varios objetivos o hipótesis. Puedes necesitar chi-cuadrado para analizar la distribución de una variable categórica, t de Student para comparar dos grupos en otra variable continua y una correlación de Spearman para explorar la relación entre una variable ordinal y una continua. Cada prueba debe estar justificada por el tipo de variables y el objetivo de esa hipótesis concreta. Lo importante es que la selección de cada prueba siga el árbol de decisión y quede explicada en la metodología.
¿Con qué software estadístico hago estas pruebas?
Las pruebas descritas en este árbol están disponibles en SPSS (el más usado en ciencias sociales y de la salud en España), jamovi (gratuito, interfaz similar a SPSS, muy adecuado para TFG), R con paquetes como rstatix o stats, y JASP (gratuito, orientado a estadística bayesiana y frecuentista). Para TFG de ciencias básicas e ingeniería también se usa Python con scipy.stats. La elección del software no cambia la prueba que debes aplicar — el árbol de decisión es independiente del software.
¿Necesitas ayuda para aplicar estas pruebas y redactar tu sección de resultados?
Tesify es la herramienta de IA diseñada para estudiantes universitarios españoles. Te guía paso a paso desde la elección del diseño metodológico hasta la redacción de los resultados y las conclusiones, con explicaciones adaptadas a tu área de conocimiento.
Prueba Tesify gratis y avanza en tu TFG o tesis con respaldo metodológico desde el primer momento.
Escribe tu TFG o tesis con IA
Pasa de la teoría a tu documento terminado
Tesify estructura, redacta y formatea tu TFG, TFM o tesis en normas APA y Vancouver, con bibliografía automática y verificación antiplagio integrada. Regístrate gratis, sin tarjeta.
Leave a Reply